Auto Mode is the setting that lets Claude Code stop interrupting developers for permission on every tool call. Instead of a human approving each action, a classifier evaluates the request against a configured policy and decides whether to run, ask, or block. By default the classifier is paranoid: it trusts only the working directory and the current repo's remotes. Everything else, like your GitHub org, cloud buckets, or internal APIs, looks like a potential exfiltration target and gets blocked.
For a single developer that paranoia is fine. For an engineering organization it has to be replaced by a policy that reflects your infrastructure: which repos are yours, which buckets you control, which services are safe to talk to, and which actions must never run regardless of intent.
We rolled that policy out across our engineering team a few weeks ago, distributed it through server-managed settings, and watched five business days of OpenTelemetry data on the other side. This post is what we shipped, how we designed it, and what the telemetry said about whether it actually moved behavior.
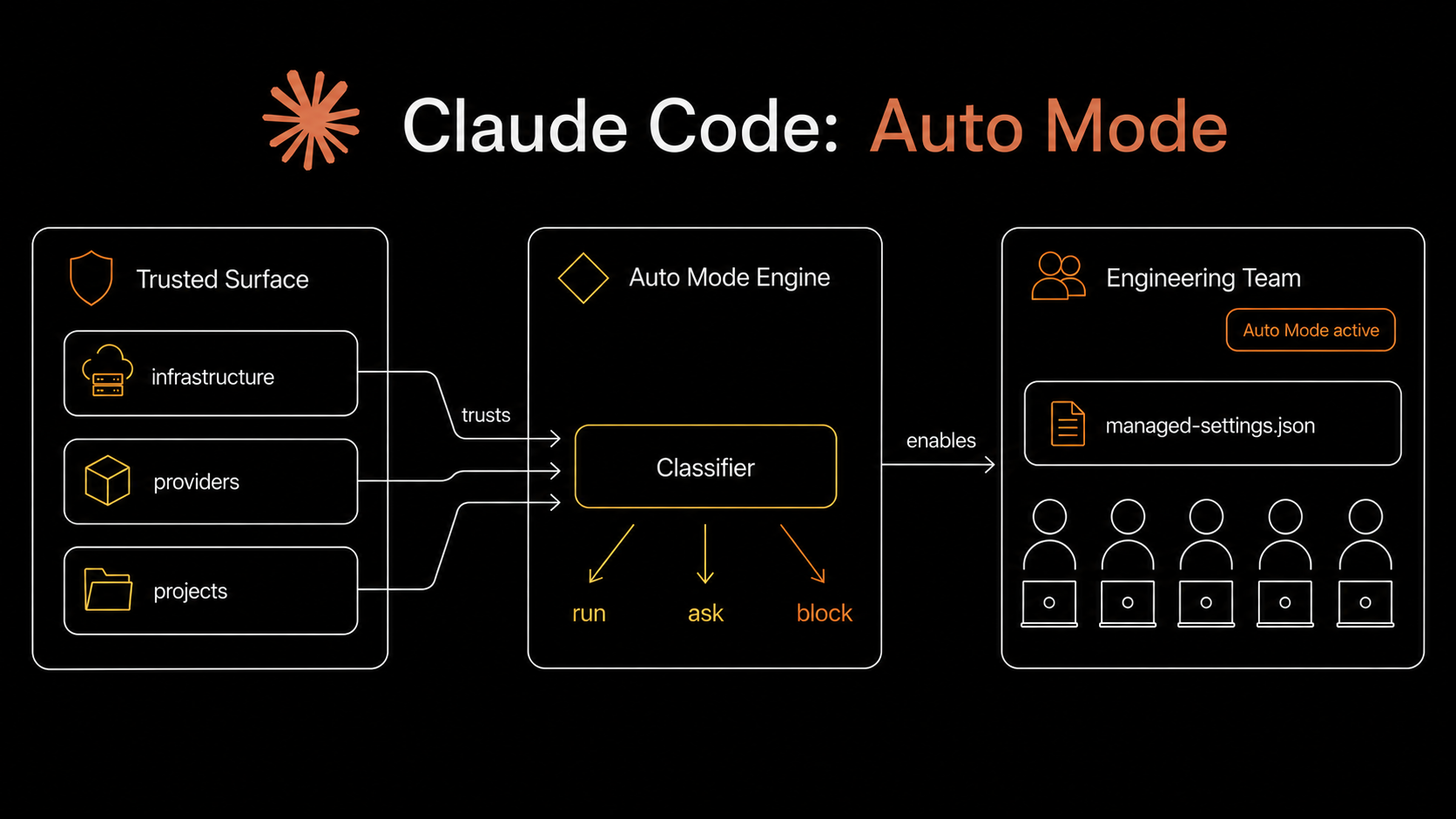
What we ship to every developer
The autoMode block lives in settings.json and has four sections. All four accept natural-language rules: prose, not regex or tool patterns.
| Section | Purpose |
|---|---|
environment | Facts about your working context (clouds, repos, internal domains, data platforms) that tell the classifier which other rules apply |
allow | An explicit allowlist of routine operations the classifier should auto-approve without prompting |
soft_deny | Block rules layered on top of the defaults; can be overridden by explicit user intent in the message |
hard_deny | Unbypassable block rules; kick the session out of Auto Mode when they fire |
There's one trap that matters more than any other:
Setting any section without including
"$defaults"replaces the entire default list for that section. Every built-in rule (force push, data exfiltration,curl | bash, production deploys) silently becomes allowed.
The shape of the policy we distribute, sanitized as a template, looks like this:
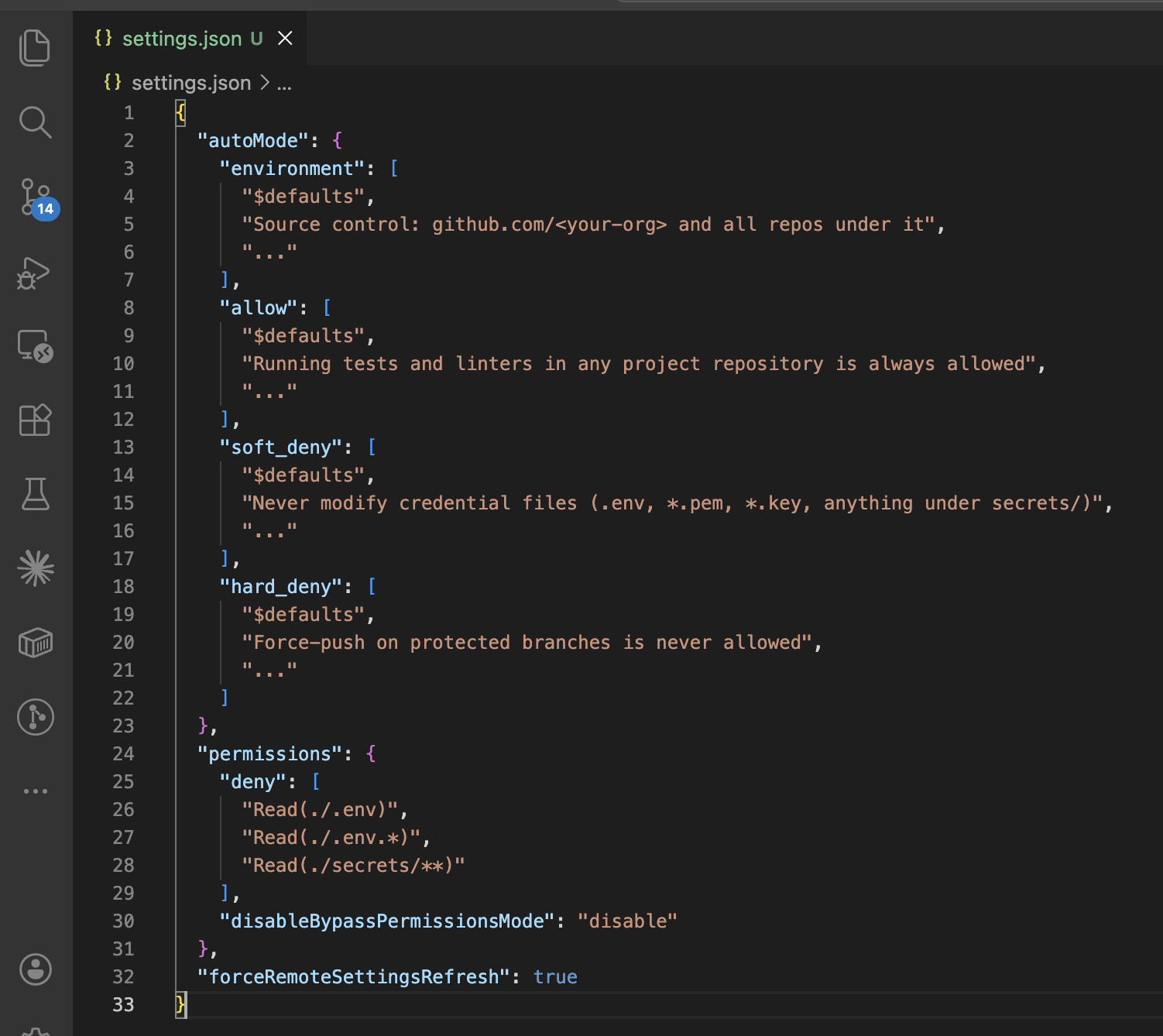
forceRemoteSettingsRefresh: true is the fail-closed switch. The CLI blocks at startup until the managed policy is freshly fetched, and exits rather than continuing without it. permissions.deny is the unbypassable layer that sits in front of the classifier entirely. Even if the classifier wanted to let an action through, permissions.deny runs first and is the right place for things that must never happen.
How we designed it
A good policy is not a brainstorm. It comes from a structured look at the surface the team actually touches.
Infrastructure. What clouds, regions, and accounts are yours? Which subdomains are internal-only, which are public? Anything in the environment field that isn't yours becomes a free pass for exfiltration; anything that is yours and isn't listed becomes friction.
Projects and repositories. Which GitHub orgs are yours? Which repos hold production code, and which directories inside the monorepo carry compliance weight (client infrastructure, secrets, migrations)? The names of these paths shape what goes into soft_deny.
Code patterns. What does the team actually do all day? Which commands and tools come up in 80% of sessions, and which ones almost never come up but, when they do, carry the most risk? The first set has to be auto-approved or the policy will be ignored. The second set is what hard_deny is for.
OTEL data: the most important input. If you have Claude Code shipping OpenTelemetry to a backend, the tool_decision event tells you exactly what your team is currently asking the model to do, what gets approved, what gets rejected, and which tools dominate the traffic. Designing a policy without that data is guessing. Designing it with that data turns the question from "what should we block" into "what is the team actually doing that the classifier doesn't yet trust."
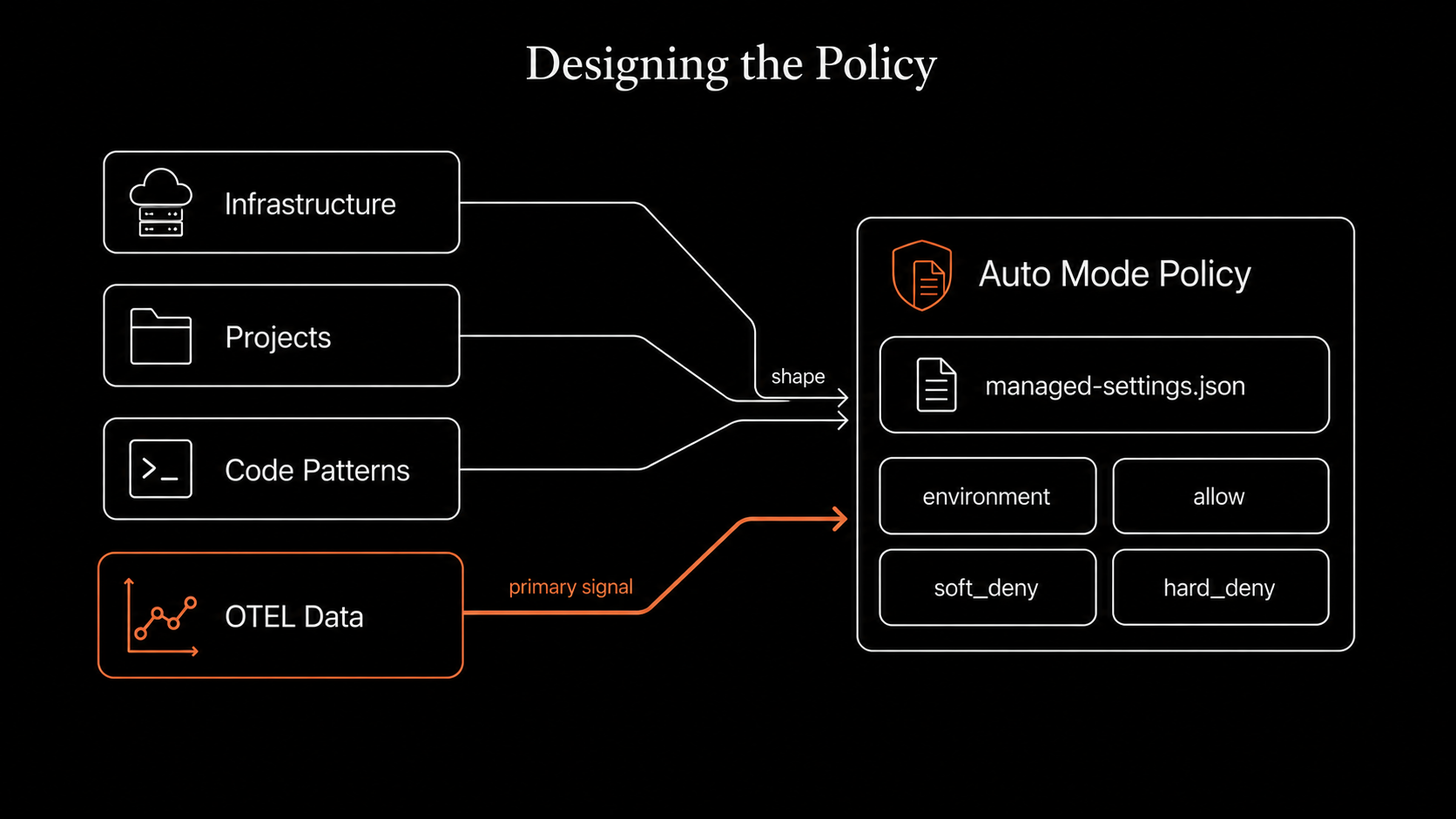
The OTEL pipeline gave us two things at design time. First, the most common Bash commands the team runs, so we knew what environment had to cover to keep them auto-approved. Second, the actions engineers were manually rejecting in pre-Auto-Mode sessions, so we knew what soft_deny had to catch. Without those, the policy would have been a list of guesses; with them, it was a list of patterns we'd already observed.
Shipping it across the team
Server-managed settings sit at the top of the configuration hierarchy. Admins push the policy through Claude.ai under Organization Settings → Claude Code → Managed settings, and clients fetch it on next startup.
Three CLI commands cover the inspection loop on every developer's machine:
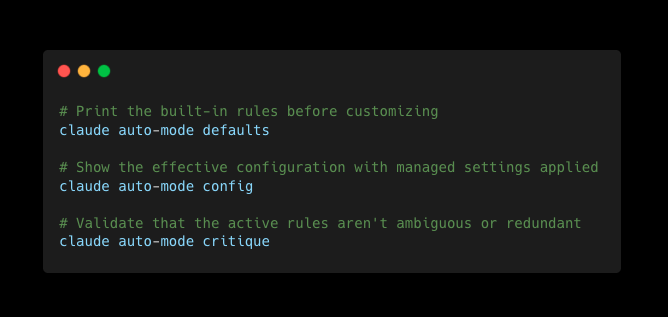
Run claude auto-mode config after every change to confirm "$defaults" expanded where you expected it to.
What the telemetry said
The interesting question isn't "did the JSON parse." It's whether the policy moved real behavior. We compared the five business days before the rollout against the five business days immediately after, with the same team, the same projects, and a comparable workload.
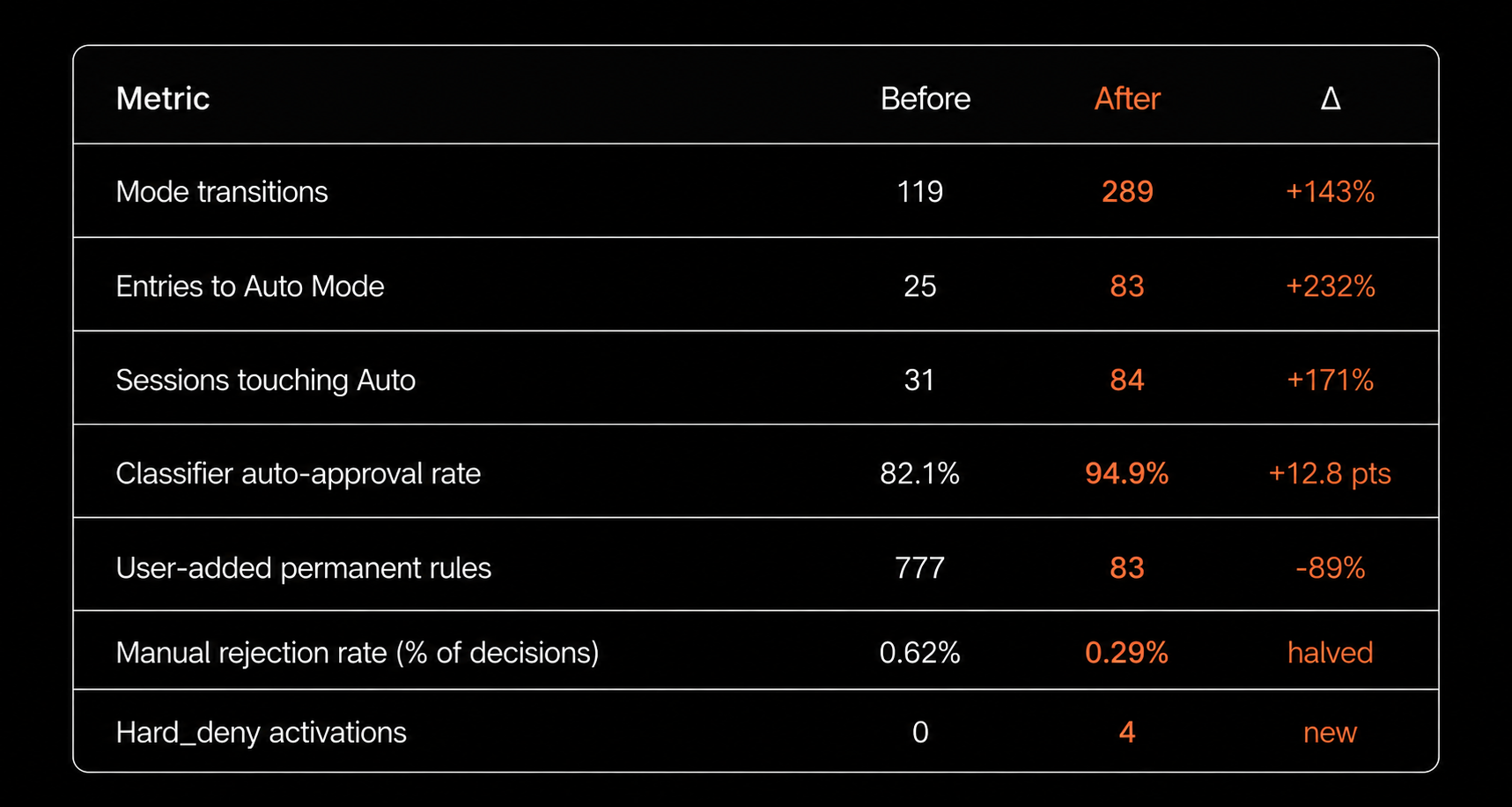
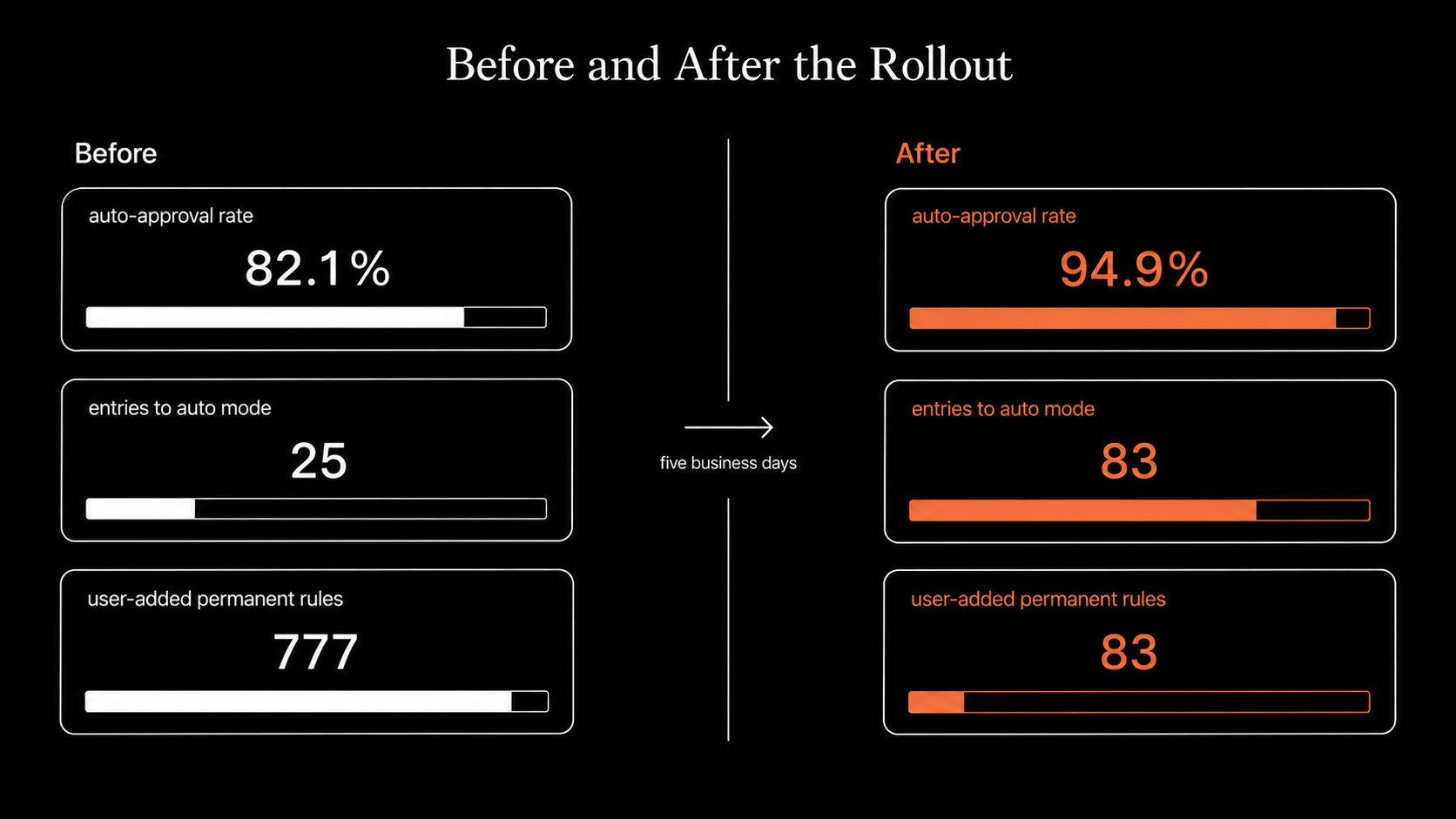
The classifier handled around 21,000 more tool decisions in the after window without the team growing meaningfully. The 89% drop in user-added permanent rules is the cleanest signal: engineers stop reaching for "always allow X" when the central policy already trusts X. When the environment description is right, people stop customizing.
What each section did
The four sections of autoMode show up differently in the data.
environment is the load-bearing piece. Auto-approval moved from 82.1% to 94.9%. That's not driven by allow, since we didn't add any custom allow rules. It's driven by environment telling the classifier that our source-control org, cloud tenants, internal domains, data platform, and package registries are trusted infrastructure. Most of the 21,000 extra auto-approved decisions are operations against that surface, the kind the default classifier would have flagged as "unknown external system" and asked about.

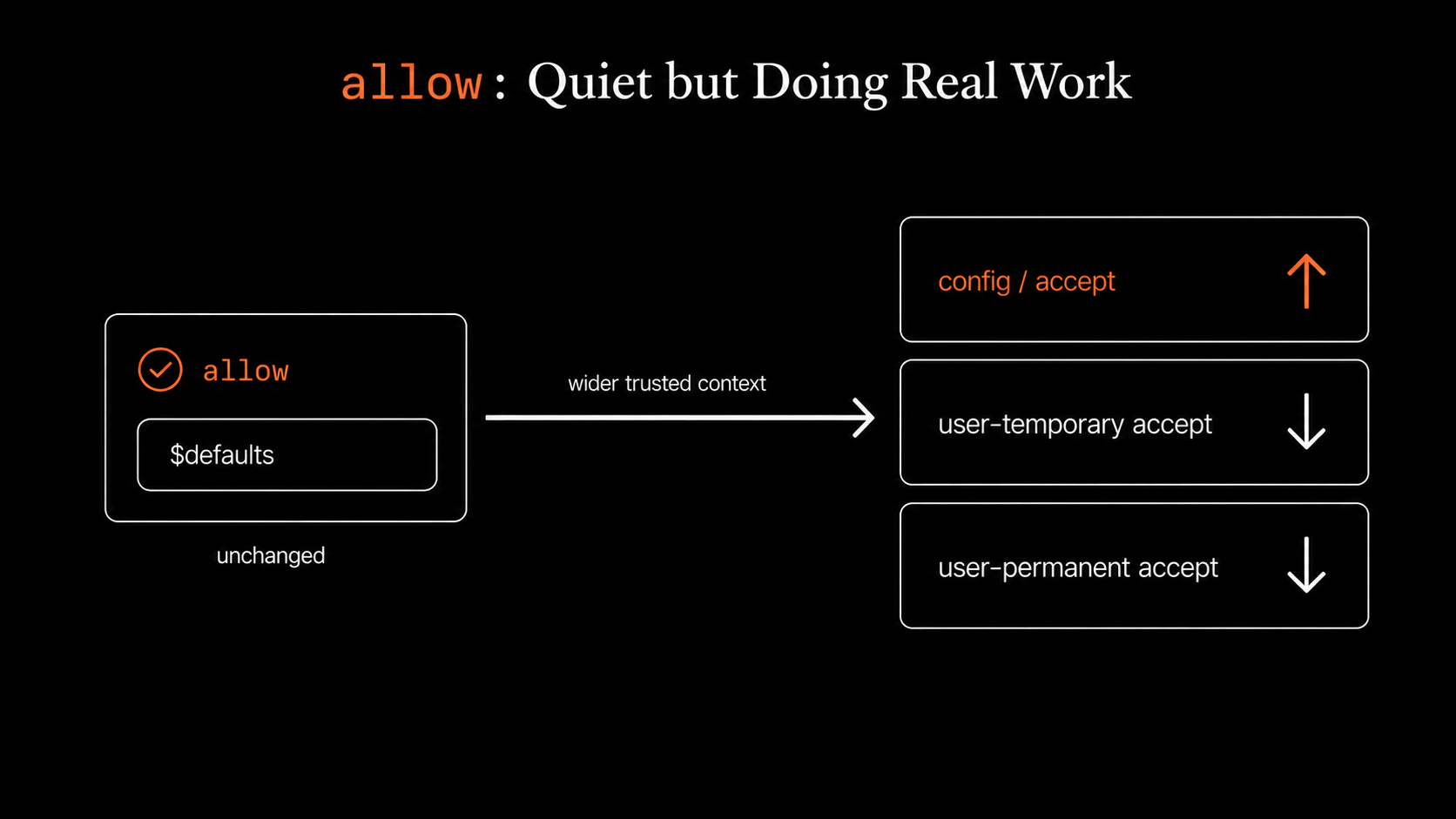
allow is quiet but doing real work. Even though we only inherited $defaults, config / accept decisions grew while user-temporary and user-permanent accepts both dropped in absolute terms. That can only happen if the existing default allow rules are catching more cases that previously needed human approval. They're being triggered against a wider set of operations now that environment has flagged the context as trusted.
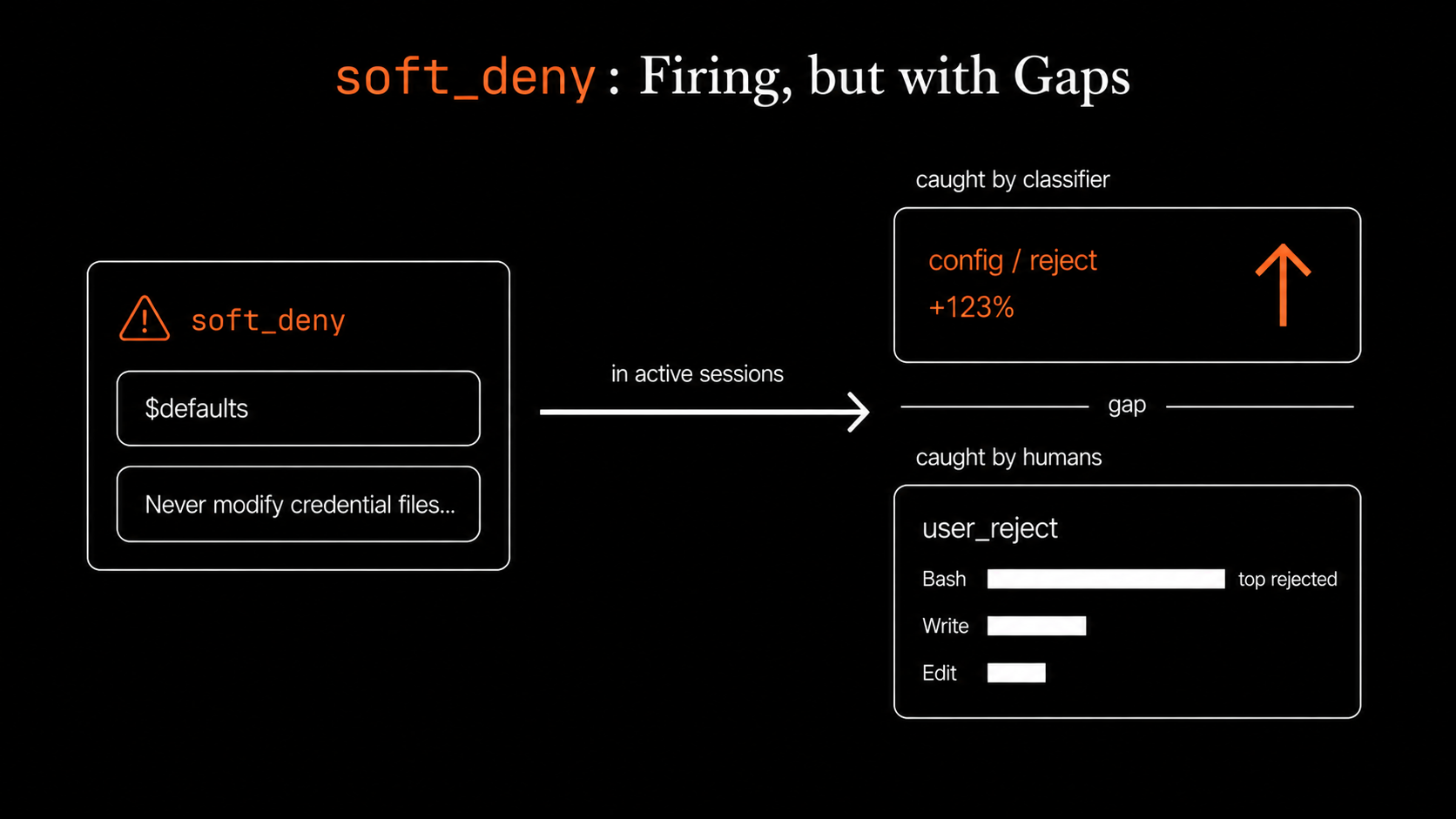
soft_deny is firing, but with gaps. config / reject decisions more than doubled (+123%), confirming the new soft_deny rules are active in real sessions. But manual user rejections, the ones the classifier let through and humans vetoed anyway, still numbered in the hundreds, with Bash as the top rejected tool by a wide margin. That's the next iteration of the policy: there are Bash commands the classifier waves through that engineers consistently say no to.
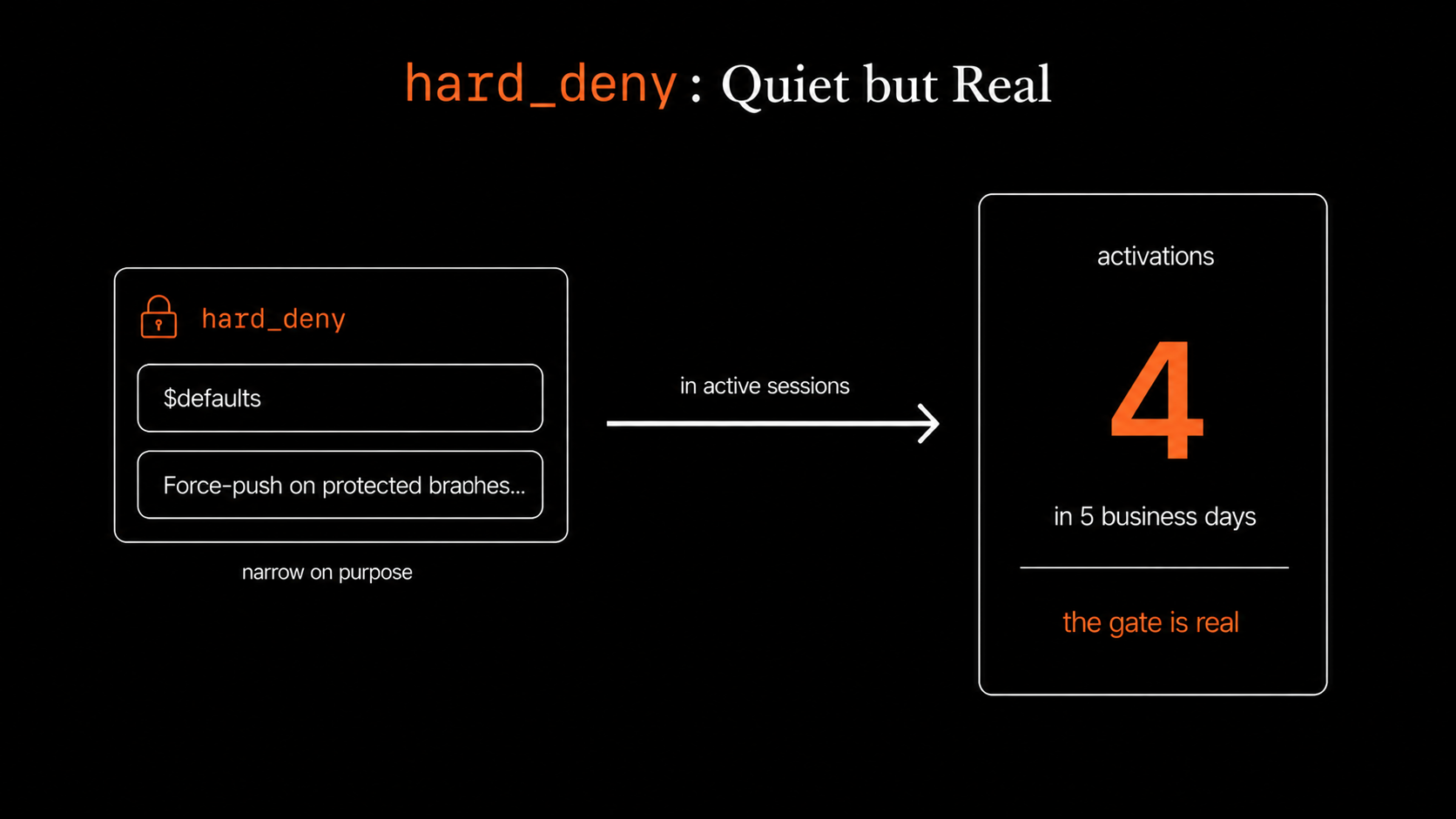
hard_deny is quiet but real. The unbypassable gate fired exactly four times in five business days. Each fire kicked the session from Auto Mode back to default mode. The rules are narrow on purpose, so four fires in a five-day window is roughly the right scale. Zero would mean either the rules are too vague to ever trigger, or no one tried the blocked behavior. Four says the gate is real.
What the data didn't show
Two gaps surfaced once we started reading the telemetry seriously.
Rule-level attribution. The tool_decision event tells us a decision was rejected by config, but not which specific rule fired. Soft_deny, hard_deny, and permissions.deny rejects all look identical in the data: source: config, decision: reject. To tune individual rules we'd need an attribute identifying which one matched. That limits how surgically we can iterate.
Bash patterns are the next iteration. Bash was the top user-rejected tool by a wide margin, and we can recover the full command for ~97% of those rejections from the telemetry. The work that's left is going through them by hand, finding the patterns that generalize, and writing them into soft_deny without over-fitting to one-off invocations. That's the next pass we'll do, and we'll revisit the results in two weeks.
Closing the loop
A policy is only as good as the data you have to evaluate it with. Writing the rules in natural-language prose, expanding $defaults correctly, and distributing through managed settings all gets you a configuration. The telemetry is what tells you the configuration shipped the behavior you actually wanted.
What we'll carry into the next iteration is small but specific: ship the OTEL instrumentation alongside the policy, not after; treat user_reject events as the most valuable signal in the data; and keep hard_deny to the smallest list that produces a handful of activations a week, so each one can be reviewed by hand. Settings without observability are guesses. Observability without a policy to validate is noise. The interesting part is putting them in the same loop.
Interested in what we're building? We're continuing to push the boundaries of AI-augmented development at Hedgineer. If you're rolling out Auto Mode across a team and want to compare notes on the policy shape or the telemetry pipeline behind it, reach out.